|
|
Programming Model |
The PULSAR programming model relies on the following five abstractions to define the processing pattern:
- Virtual Systolic Array (VSA) is a set of VDPs connected with channels.
- Virtual Data Processor (VDP) is the basic processing element in the VSA.
- Channel is a point-to-point connection between a pair of VDPs.
- Packet is the basic unit of information transferred in a channel.
- Tuple is a unique VDP identifier.
It also relies on the following two abstractions to map the processing pattern to the actual hardware:
- Thread is synonymous with a CPU thread or a collection of threads.
- Device is synonymous with an accelerator device (GPU, Xeon Phi, etc.)
The sections to follow describe the roles of the different entities, how the VDP operation is defined, how the VSA is constructed, and how the VSA is mapped to the hardware. These operations are accessible to the user through PULSAR's Application Programming Interface (API), which is currently available with C bindings. |
Tuple |
Tuples are strings of integers. Each VDP is uniquely identified by a tuple. Tuples can be of any length, and different length tuples can be used in the same VSA. Two tuples are identical if they are of the same length and have identical values of all components. Tuples are created using the variadic function prt_tuple_new(), which takes a (variable length) list of integers as its input. The user only creates tuples. After creation, tuples are passed to VDP constructors and channel constructors. They are destroyed by the runtime at the time of destroying those objects. As a general rule in PULSAR, the user only creates objects, and looses their ownership after passing them to the runtime. |
Packet |
Packets are basic units of information exchanged through channels connecting VDPs. A packet contains a reference to a continuous piece of memory of a given size. Conceptually, packets are created by VDPs. The user can use the VDP function prt_vdp_packet_new() to create a new packet. A packet can be created from preallocated memory by providing the pointer. Alternatively, new memory can be allocated by providing a NULL pointer. The VDP can fetch a packet from an input channel using the function prt_vdp_channel_pop(), and push a packet to an output channel using the function prt_vdp_channel_push(). The VDP does not loose the ownership of the packet after pushing it to a channel. The packet can be used until the prt_vdp_packet_release() function is called, which discards it. |
Channel |
Channels are unidirectional point-to-point connections between VDPs, used to exchange packets. Each VDP has a set of input channels and a set of output channels. Packets can be fetched from input channels and pushed to output channels. Channels in each set are assigned consecutive numbers starting from zero (slots). Channels are created by using the prt_channel_new() function. The user does not destroy channels. The runtime destroys channels at the time of destroying the VDP. After creation, each channel has to be inserted in the appropriate VDP, using the prt_vdp_channel_insert() function. The user has to insert a full set of channels into each VDP. At the time of inserting the VDP in the VSA, the system joins channels that identify the same communication path. |
Virtual Data Processor |
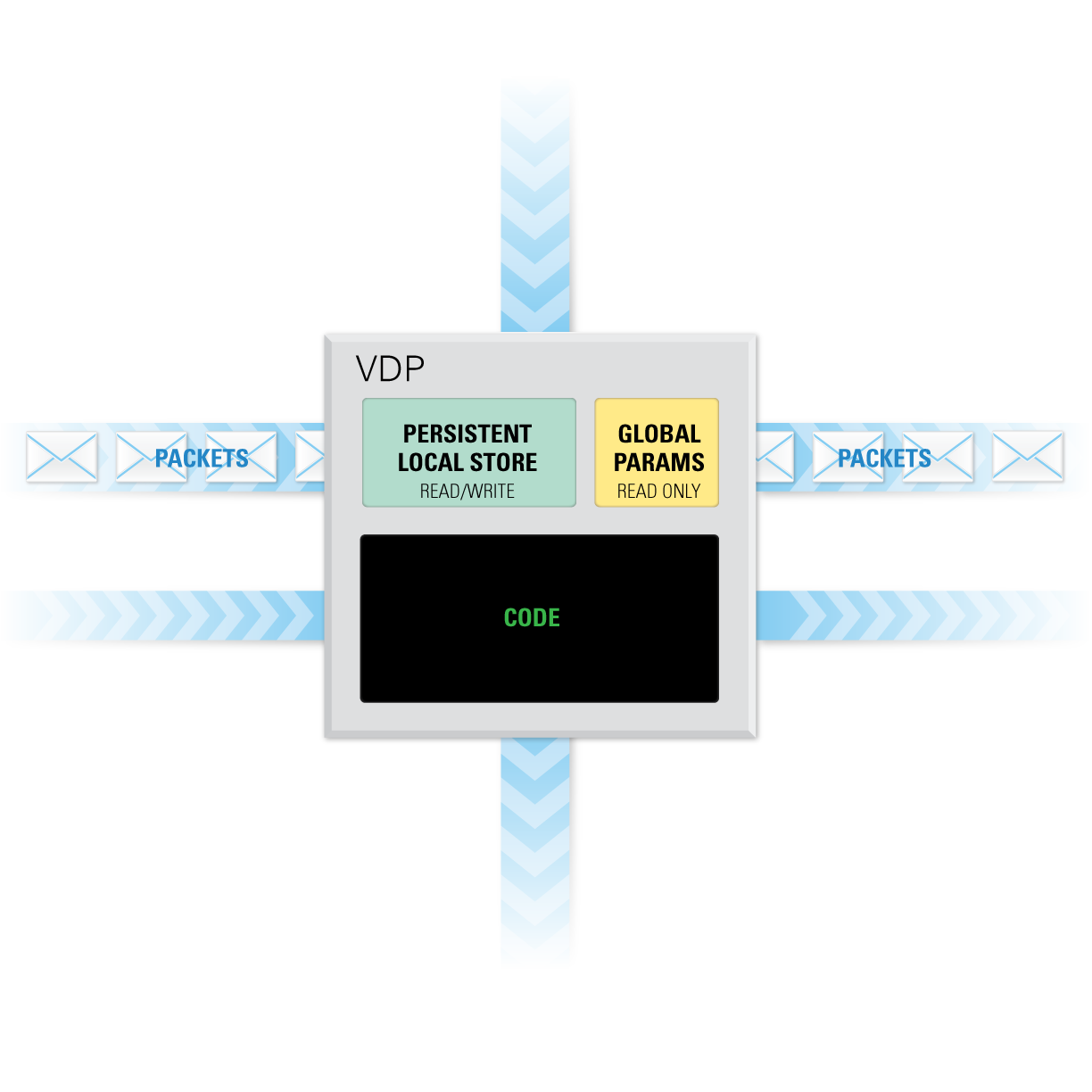 The VDP is the basic processing element of the VSA. Each VDP is uniquely identified by a tuple and assigned a function which defines its operation. Within that function, the VDP has access to a set of global parameters, its private, persistent local storage, and its channels. The runtime invokes that function when there are packets in all of the VDP's input channels. This is called firing. When the VDP fires, it can fetch packets from its input channels, call computational kernels, and push packets to its output channels. It is not required that these operations are invoked in any particular order. The VDP fires a prescribed number of times. When the VDP's counter goes down to zero, the VDP is destroyed. The VDP has access to its tuple and its counter. Here are some typical VDP processing patterns: The VDP is the basic processing element of the VSA. Each VDP is uniquely identified by a tuple and assigned a function which defines its operation. Within that function, the VDP has access to a set of global parameters, its private, persistent local storage, and its channels. The runtime invokes that function when there are packets in all of the VDP's input channels. This is called firing. When the VDP fires, it can fetch packets from its input channels, call computational kernels, and push packets to its output channels. It is not required that these operations are invoked in any particular order. The VDP fires a prescribed number of times. When the VDP's counter goes down to zero, the VDP is destroyed. The VDP has access to its tuple and its counter. Here are some typical VDP processing patterns:
prt_packet_t *packet = prt_vdp_packet_new(vdp, ...);
kernel_that_writes(..., packet->data, ...);
prt_vdp_channel_push(vdp, slot, packet);
prt_vdp_packet_release(vdp, packet);
prt_packet_t *packet = prt_vdp_channel_pop(vdp, slot);
kernel_that_modifies(..., packet->data, ...);
prt_vdp_channel_push(vdp, slot, packet);
prt_vdp_packet_release(vdp, packet);
prt_packet_t *packet = prt_vdp_channel_pop(vdp, slot);
prt_vdp_channel_push(vdp, slot, packet);
kernel_that_reads(..., packet->data, ...);
prt_vdp_packet_release(vdp, packet);
At the time of the VDP creation, the user specifies if the VDP resides on a CPU or on an accelerator. This is an important distinction, because the code of a CPU VDP has synchronous semantics, while the code of an accelerator VDP has asynchronous semantics. For a CPU VDP, actions are executed as they are invoked, while for an accelerator VDP, actions are queued for execution after preceding actions complete. In the CUDA implementation, each VDP has its own stream. All kernel invocations have to be asynchronous calls, placed in the VDP's stream. The runtime will also place all channel operations in the VDP's stream. |
Virtual Systolic Array |
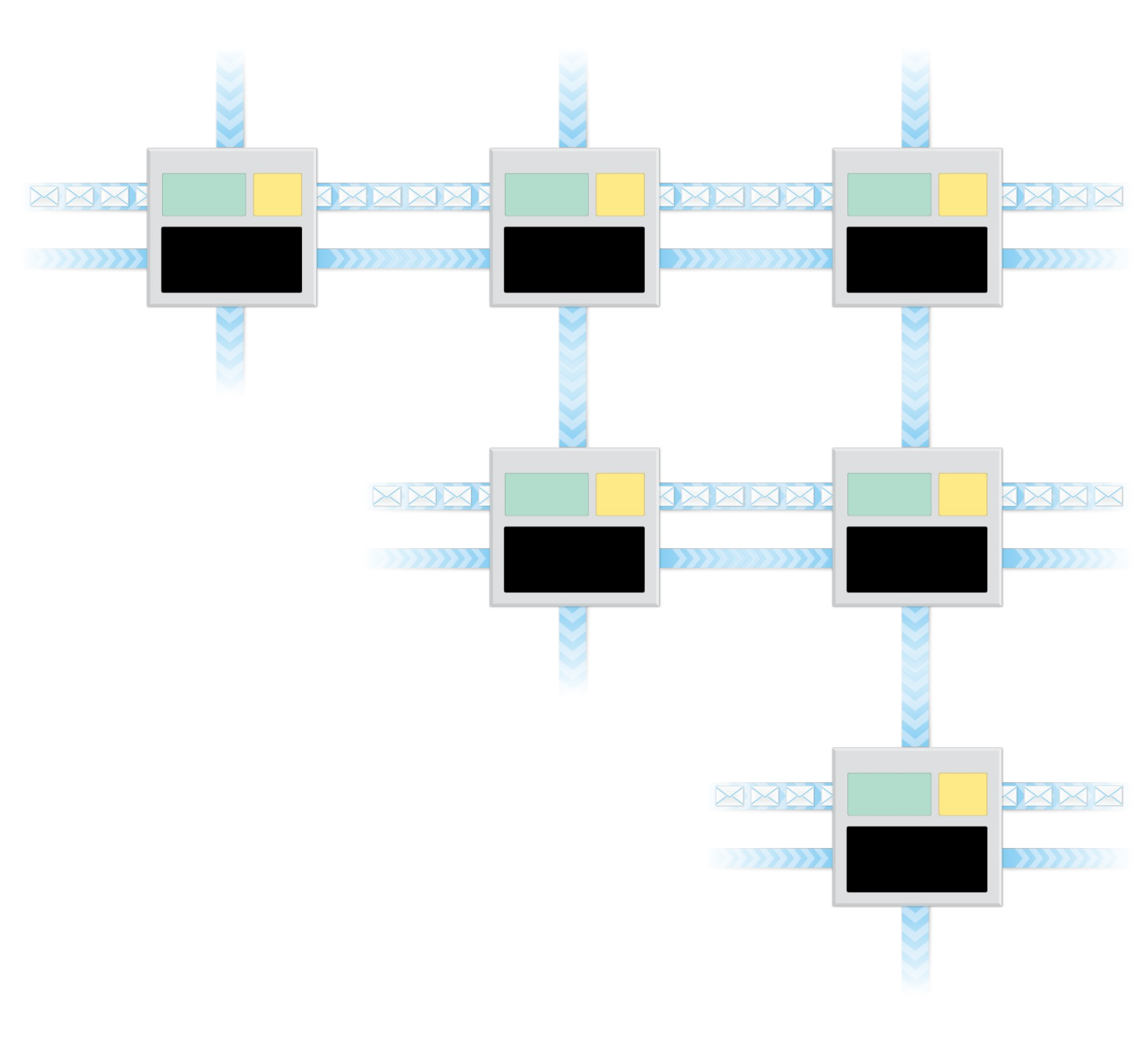 VSA contains all VDPs and their channel connections, and stores the information about the mapping of VDPs to the hardware. The VSA needs to be created first and then launched. An empty VSA is created using the prt_vsa_new() function. Then VDPs can be inserted in the VSA using the prt_vsa_vdp_insert() function. Then the VSA can be executed using the prt_vsa_run() function, and then destroyed using the prt_vsa_delete() function. Here is a typical VSA construction and execution process. VSA contains all VDPs and their channel connections, and stores the information about the mapping of VDPs to the hardware. The VSA needs to be created first and then launched. An empty VSA is created using the prt_vsa_new() function. Then VDPs can be inserted in the VSA using the prt_vsa_vdp_insert() function. Then the VSA can be executed using the prt_vsa_run() function, and then destroyed using the prt_vsa_delete() function. Here is a typical VSA construction and execution process.
prt_vsa_t *vsa = prt_vsa_new(num_threads, num_devices, ...);
for (v = 0; v < vdps; v++) {
prt_vdp_t *vdp = prt_vdp_new(...);
for (in = 0; in < inputs; in++) {
prt_channel_t *input = prt_channel_new(...);
prt_vdp_channel_insert(vdp, input, ...);
}
for (out = 0; out < outputs; out++) {
prt_channel_t *output = prt_channel_new(...);
prt_vdp_channel_insert(vdp, output, ...)
}
prt_vsa_vdp_insert(vsa, vdp, ...);
}
double time = prt_vsa_run(vsa);
prt_vsa_delete(vsa);
At the time of creation, using the prt_vsa_new() function, the user provides the number of CPU threads to launch per each distributed memory node, and the number of accelerator devices to use per each node. The user also provides a function for mapping VDPs to threads and devices. The function takes as parameters: the VDP's tuple, the total number of threads, and the total number of devices, and returns a structure indicating if the VDP is assigned to a thread or a device, and the global rank of the thread or device, where the VPD resides.
VSA construction can be replicated or distributed. The replicated construction is more straightforward, from the user's perspective. In the replicated construction, each MPI process inserts all the VDPs, and the system filters out the ones that do not belong in a given node, based on the mapping function. However, the VSA construction process is inherently distributed, so each process can also insert only the VDPs that belong in that process.
|
Multicore + MPI |
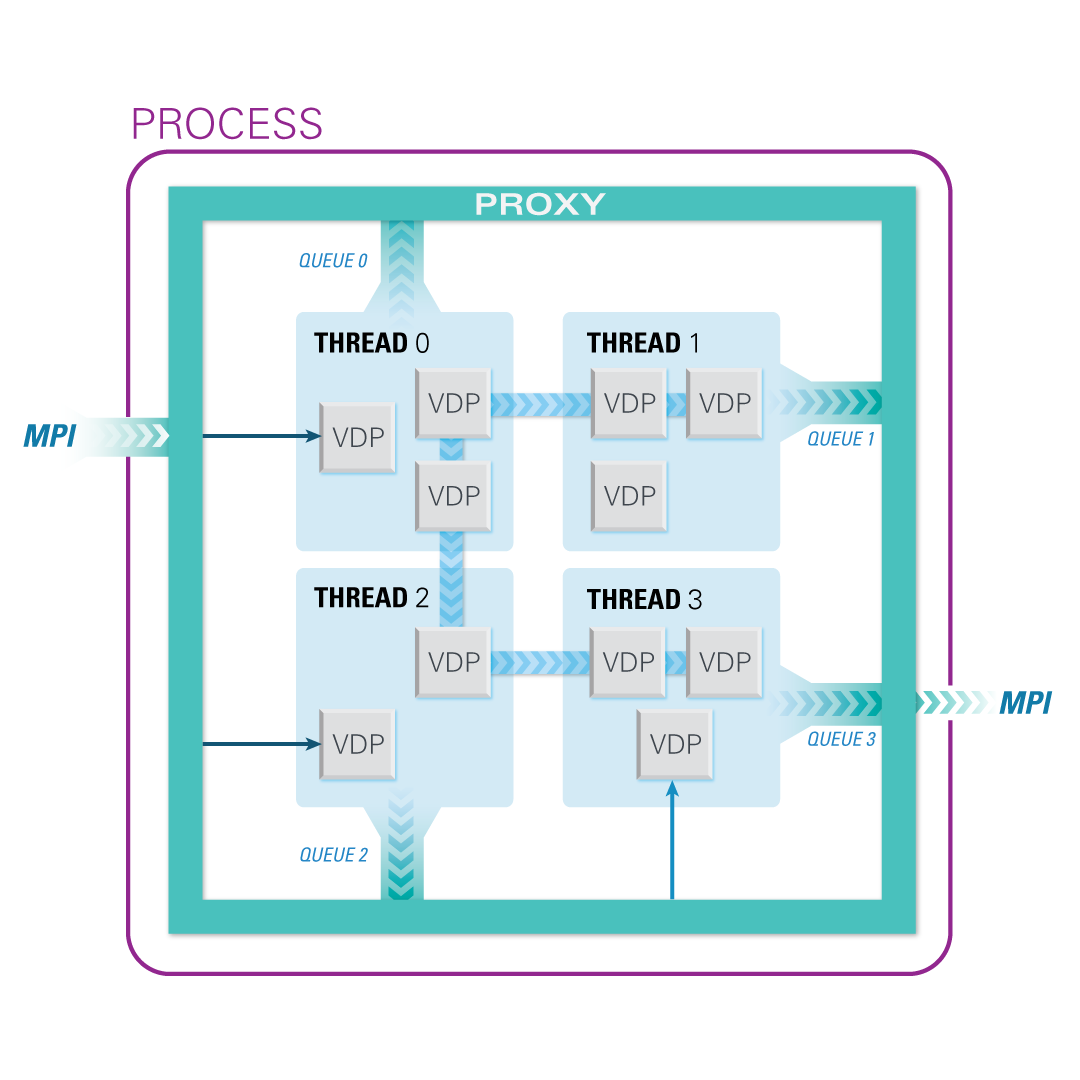 PULSAR runtime can handle the complexity of multithreading within each node and message-passing among all nodes. PULSAR runtime can handle the complexity of multithreading within each node and message-passing among all nodes.
|
Multicore + GPU + MPI |
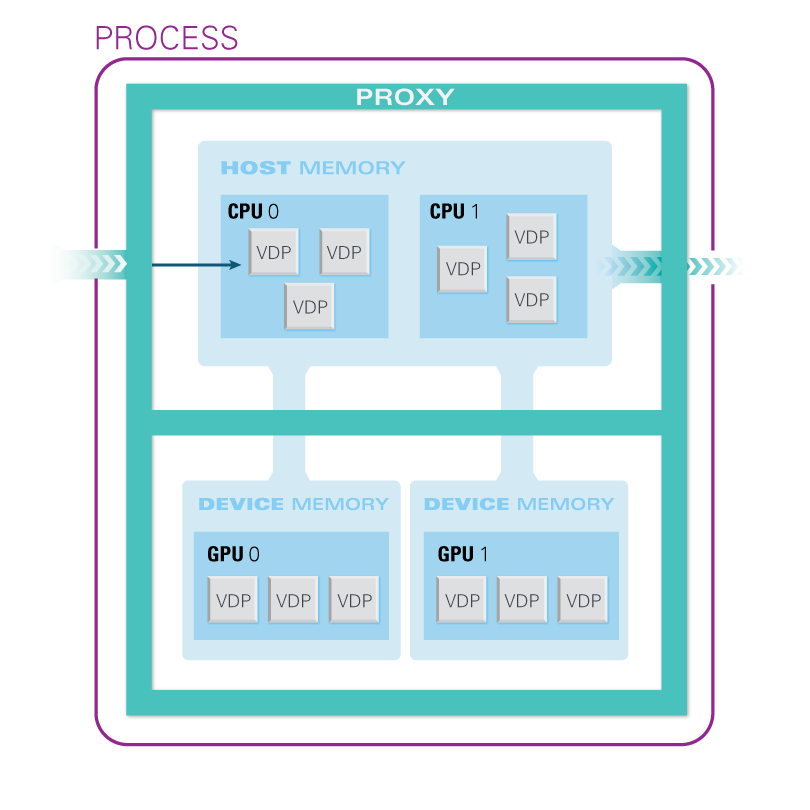 PULSAR runtime can also handle the complexity of multithreading and GPU acceleration within each node, and message-passing among all nodes. PULSAR runtime can also handle the complexity of multithreading and GPU acceleration within each node, and message-passing among all nodes.
|
Project Handouts
|


